機器學習演算法學得好不好,其中一個關鍵是數據及資料的品質。所以要對資料做預處理,能夠幫助我們構建更好的機器學習模型。
處理數據缺失
現實中常會因為各種原因,造成數據總是存在或多或少的缺失值現象。可能是數據收集階段發生錯誤,數據沒有被填寫,某些量測不適用。不論是什麼原因造成的缺失值,我們都會將其看做空格或者用NaN表示的佔位符。
不幸地是,大多數計算工具不能處理缺失值,即使我們忽略缺失值也不能產生預測結果。因此,我們必須認真對待缺失值問題。在討論處理缺失值的方法之前,我們先創建一個例子,以便更好地理解缺失值問題:
import pandas as pd
from io import StringIO
csv_data = '''
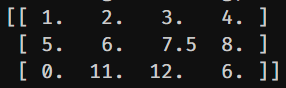
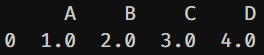
A, B, C, D
1.0, 2.0, 3.0, 4.0
5.0, 6.0,, 8.0
0.0, 11.0, 12.0'''
df = pd.read_csv(StringIO())
執行上面的程式碼,我們將一個CSV格式的數據,藉由pandas的read_csv函數,讀入DataFrame中。可以很明顯發現,有兩個格子的數據遺失了,以NAN來表示,結果如下圖所示:
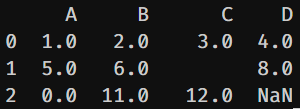
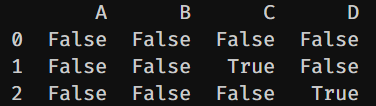
如果DataFrame對象包含的數據很多,人工來找NaN是非常繁瑣的。所以可以用isnull檢查Dataframe是否有NAN。如果某一格有遺漏時,isnull會回傳True,反之為False。
df.isnull()
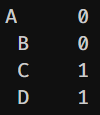
可以用sum()方法對每一行NAN數量做統計
df.isnull().sum()
刪除有NAN的特徵所以或樣本
因為有時候遺漏值對訓練模型會產生影響,所以刪除有遺漏值的某一筆資料(列)或是刪除有遺漏值的某一個特徵(行)必要的,可以透過dropna來完成
df.dropna()
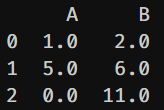
df.dropna(axis=1)
df.dropna還有其他方便的參數處理資料
# 把全都是NAN的row drop掉
df.dropna(how='all')
# 把非NAN不足4個的row drop掉
df.dropna(thresh=4)
# 把所指定且有NAN的column drop掉
df.dropna(subset=['A'])
其實向上面這樣貿然將遺漏值刪除,會刪除過多的資料數,遺失重要資訊,所以另一個常用的方法叫做interpolation techniques,下面的範例是將遺失值以每一行平均值代替,你也可以改變axis=1(列的平均),你也可以改變strategy='median'(中位數) or 'most_frequent'(眾數)
from sklearn.preprocessing import Imputer
imr = Imputer(missing_values='NaN', strategy='mean', axis=0)
imr = imr.fit(df)
imputed_data = imr.transform(df.values)